After compiling fastGPT in September 2023, today we are happy to announce that LFortran can compile and run dftatom without any modifications, and dftatom’s continuous integration (CI) now tests every commit with LFortran, along side GFortran.
This is the fourth full third-party production-grade code that LFortran can compile. The progress bar towards beta has thus reached 4/10.
It can compile the main application in Debug mode twice faster than GFortran. In Release mode the runtime performance is within a factor of 2x slower than GFortran’s Release mode (all optimizations on).
LFortran is still alpha software, meaning that users must continue expecting that LFortran will fail compiling or running their codes. This means it is still easy to find compiler bugs and every time you find one, you should celebrate and then please report it. As we reach beta and later production, it will become a lot harder to find them.
dftatom Overview
dftatom is a library that implements accurate and efficient shooting-method solvers for the electronic-structure atomic radial Schrödinger and Dirac equations in the context of Density Functional Theory (DFT). You can read more information and link to an article explaining how it works in the README, see the project link above. Here are the main Fortran modules and functions:
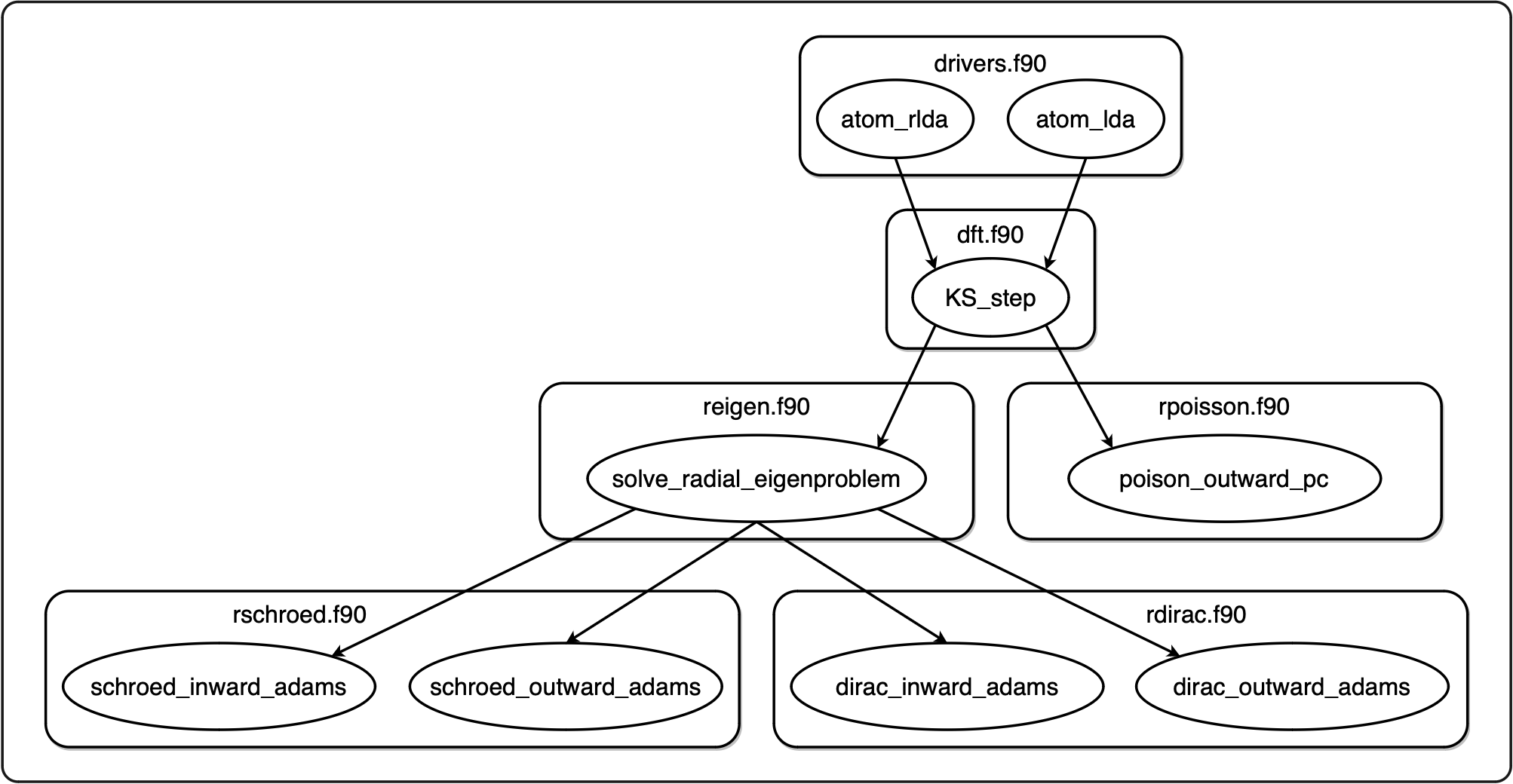
The code is written in modern Fortran, utilizing many common idioms such as allocatable arrays, derived types, string formatting and many array operations. While the fastGPT code exercised some of these features, dftatom uses many more combinations typically used in practice. Being able to compile it means LFortran is becoming very usable (although still alpha) for typical computational physics calculations. There are two build systems, manual makefiles with 3 tests and cmake with 21 tests. Both work with LFortran and all tests pass.
As an example, here is the output generated by LFortran for F_atom_U, the non-relativistic Uranium atomic calculation using local-density approximation (LDA) in DFT:
$ ./F_atom_U
Z= 92 N= 5500
E_tot= -25658.417889 a.u.
state E [a.u.] occupancy
1s -3689.355140 2.000
2s -639.778728 2.000
2p -619.108550 6.000
3s -161.118073 2.000
3p -150.978980 6.000
3d -131.977358 10.000
4s -40.528084 2.000
4p -35.853321 6.000
4d -27.123212 10.000
4f -15.027460 14.000
5s -8.824089 2.000
5p -7.018092 6.000
5d -3.866175 10.000
5f -0.366543 3.000
6s -1.325976 2.000
6p -0.822538 6.000
6d -0.143190 1.000
7s -0.130948 2.000
Print the first 10 values of the 1st and 2nd orbitals:
1.75328926418836136e+03 1.75328121752118705e+03 1.75327315125316363e+03 1.75326506454811920e+03 1.75325694958405666e+03 1.75324882035547853e+03 1.75324067107709357e+03 1.75323250147954241e+03 1.75322431102506198e+03 1.75321609934958383e+03
5.87507022963877034e+02 5.87504326614959496e+02 5.87501623693095667e+02 5.87498913919208576e+02 5.87496194672607658e+02 5.87493470642835518e+02 5.87490739891368435e+02 5.87488002327970548e+02 5.87485257772447085e+02 5.87482506102796833e+02
The energies are in Hartree atomic units.
Benchmarking
Following are benchmarks run on different systems. We test Debug and Release modes. The Debug mode has slow runtime but fast compilation. The Release mode has fast runtime but slow compilation.
For Debug mode we use no flags for LFortran nor GFortran. For Release mode we use the following optimization flags for GFortran: -O3 -march=native -ffast-math -funroll-loops, and the following for LFortran: --skip-pass=inline_function_calls,fma --fast.
Compilation benchmarks
FC=gfortran cmake -DCMAKE_BUILD_TYPE=Debug .
time make conv_lda
gfortran 13.2.0 on MacBook Pro M1 (2020):
make conv_lda 3.33s user 0.64s system 104% cpu 3.811 total
lfortran 0.29.0 on MacBook Pro M1 (2020):
make conv_lda 1.40s user 0.33s system 96% cpu 1.796 total
On this particular benchmark, platform and compiler versions, LFortran is about 2.1x faster to compile. A significant amount of LFortran’s total compilation time is spent in LLVM (which in Debug mode just emits a binary with no optimizations), so our plan is to experiment with a custom faster backend for Debug builds to speedup compilation even further.
LFortran compiles each Fortran module file to a .mod file which is just a serialized ASR (our intermediate representation). It does full parsing and semantics, but no other processing. GFortran also generates .mod files, but only stores the interfaces to modules (not the whole intermediate representation) and in addition it compiles to object files too (LFortran can do that using the --generate-object-code option as well, but currently it is mostly tested with compiling the Fortran packages in SciPy, which do not use modules).
If we compile all binaries, not just one, then LFortran’s compilation is slower (as one can see on the benchmarks in the next section), because it currently generates all code from scratch for each binary, not reusing precompiled object files like GFortran does. We will address this issue in the future.
Compilation and Run Time Benchmarks
Apple MacBook Pro M2 Pro (16 GB Memory)
Full run of the conv_lda (Schrödinger) and conv_rlda (Dirac) DFT tests for all atoms from Hydrogen (Z=1) to Uranium (Z=92) and all accuracies from 1e-3 to 1e-8.
| Compiler | Compile Time (s) | Run Time (conv_lda) (s) |
Run Time (conv_rlda) (s) |
|---|---|---|---|
| GFortran 11.0.1 Debug | 1.859 | 57.633 | 105.45 |
| LFortran 0.25.0 Debug | 2.625 | 186.28 | 356.37 |
| GFortran 11.0.1 Release | 4.467 | 34.288 | 61.86 |
| LFortran 0.25.0 Release | 5.622 | 53.134 | 100.04 |
As you can see, LFortran is within a factor of 2x slower for the Release runs.
Apple MacBook Pro M1 (16 GB Memory)
For the Uranium atom
| Compiler | Compile Time (s) | Run Time (conv_lda) (s) |
Run Time (conv_rlda) (s) |
|---|---|---|---|
| GFortran 12.2.0 | 1.542 | 1.890 | 3.271 |
| LFortran 0.25.0 | 3.541 | 5.766 | 10.963 |
| GFortran 12.2.0 (Optimised) | 4.384 | 1.042 | 1.795 |
| LFortran 0.25.0 (Optimised) | 5.936 | 1.662 | 3.177 |
For all atoms
| Compiler | Compile Time (s) | Run Time (conv_lda) (s) |
Run Time (conv_rlda) (s) |
|---|---|---|---|
| GFortran 12.2.0 | 1.571 | 65.382 | 117.468 |
| LFortran 0.25.0 | 3.559 | 192.796 | 375.302 |
| GFortran 12.2.0 (Optimised) | 4.391 | 36.992 | 66.708 |
| LFortran 0.25.0 (Optimised) | 5.958 | 55.492 | 106.969 |
AMD Ryzen 5 2500U (Ubuntu 22.04, 20 GB Memory)
For the Uranium atom
| Compiler | Compile Time (s) | Run Time (conv_lda) (s) |
Run Time (conv_rlda) (s) |
|---|---|---|---|
| GFortran 11.4.0 | 2.141 | 3.654 | 6.574 |
| LFortran 0.25.0 | 8.473 | 13.422 | 22.948 |
| GFortran 11.4.0 (Optimised) | 7.609 | 1.413 | 2.309 |
| LFortran 0.25.0 (Optimised) | 17.029 | 2.769 | 5.662 |
For all atoms
| Compiler | Compile Time (s) | Run Time (conv_lda) (s) |
Run Time (conv_rlda) (s) |
|---|---|---|---|
| GFortran 11.4.0 | 2.124 | 93.026 | 180.604 |
| LFortran 0.25.0 | 6.376 | 369.006 | 712.956 |
| GFortran 11.4.0 (Optimised) | 6.837 | 41.754 | 75.532 |
| LFortran 0.25.0 (Optimised) | 16.040 | 81.498 | 171.116 |
Benchmarking Discussion
The benchmarks are preliminary, the numbers will change as LFortran matures, the main purpose is to give an idea what to expect about LFortran’s current alpha-version compilation and run time performance.
The compilation time of LFortran are within a factor of 1.5 of GFortran’s because we compile several binaries (see the previous benchmark where we compile just one binary and then LFortran is faster than GFortran to compile). The run time for the unoptimized version are considerably slower than those of GFortran, but for the optimised version they are within a factor of 2 of GFortran’s. This is a decent performance, given that LFortran is still in alpha. Once LFortran reaches beta, we will focus on optimizations, with the objective to match or beat GFortran’s run time in all cases. GFortran is the most advanced and mature production open source Fortran compiler.
We encourage you to try LFortran via conda-forge using conda install lfortran which works on Linux, MacOS Intel/M1 and Windows. Note: the Windows platform is less tested, but Linux and macOS should work for everything we discussed above. As we reach beta, we will ensure that everything works on Windows as well.
Run the benchmarks yourself, report bugs and let us know any feedback that you might have.
What’s Next?
As of this writing, LFortran compiles four third-party codes:
- Legacy Minpack (part of SciPy) and several more SciPy packages
- Modern Minpack
- fastGPT
- dftatom
Our goal is to compile 10 third-party codes so as to bring LFortran from alpha to beta. This is our main focus. We have been working on compiling several more third-party codes. Our progress roadmap is essentially a “feature importance” method where LFortran supports all language features that show up in the ten third-party candidate codes. Since these codes are taken as representative of existing Fortran codes, compiling them (and supporting the language features used) is how it is used as a metric for progress towards beta. We will continue to announce each one as soon as we are able to fully compile and run them unchanged from their source code. Some of those codes are the Fortran Package Manager (fpm), Fortran stdlib and large parts of SciPy. The requirement and milestone to compile 10 third-party codes is necessary to reach beta, but might not be sufficient. Once we deliver the milestone we will evaluate with the community what else needs to be done to get to beta. Our definition of beta quality compiler is that when you run it on your code, it is expected to work and not fail, but there might still be bugs.
We are always looking for more contributors; if you are interested, please get in touch. It is an exciting time of delivering LFortran, it is becoming easier and easier to compile new codes and it is a lot of fun to work on a compiler and learn how it works. We will teach you all the skills needed.
Acknowledgements
We’d like to thank GSI Technology for supporting this work. GSI recognizes the importance of compiler technology and benchmarking for all devices: CPU, GPU, and their own APU (Associative Processing Unit). LFortran is especially attractive to GSI because of its array orientation, and GSI’s APU is an array-processing accelerator.
We also want to thank:
- LANL
- NumFOCUS
- Sovereign Tech Fund (STF)
- QuantStack
- Google Summer of Code
- Our GitHub, OpenCollective and NumFOCUS sponsors
- All our contributors (65 so far!)