After successful compilation of stdlib and Fortran On Web Using LFortran, we focused on improving the support for compile time computation and we are excited to announce that LFortran can now compile the example from the Computing at compile time Fortran Discourse topic.
This example can be used to benchmark the speed of compilation and compile-time array evaluation by increasing the size of the arrays. On this particular example LFortran outperforms other open-source Fortran compilers by an order of magnitude for large array sizes. For small array sizes each compiler has a different constant overhead, which becomes negligible for large arrays and this benchmark measures how quickly the compiler can internally apply the symbolic function on a large array numerically.
You can try LFortran yourself on other examples and if you find that other compilers significantly outperform it in the speed of compilation, please let us know.
Why care about the speed of compilation? When developing large Fortran codes, it is essential to compile as quickly as possible to make the edit-compile-run cycle short. It must be a pleasure to develop in Fortran. Fast compilation, beautiful error messages both at compile time and runtime in Debug mode (no segfaults).
When running in production, we then want the fastest performance at runtime. LFortran’s goal is to be fast to compile in Debug mode and fast to run in Release mode.
LFortran is currently alpha software, meaning that users must continue expecting that LFortran will fail compiling or running their codes. Please report all bugs that you find.
Compilation Benchmark
The following program computes the integral of sin(x) from 0 to pi at compile-time using the simplest linear approximation:
compile_time.f90
program compile_time
implicit none
integer, parameter :: N = 65535
integer, parameter :: sp = kind(1.0)
integer, parameter :: dp = kind(1.d0)
real(dp), parameter :: pi = 2*asin(1._dp)
real(dp), parameter :: a = 0, b = pi
real(dp), parameter :: dx = (b-a)/N
integer :: i
real(dp), parameter :: X(*) = [(sin(a+(b-a)*i/N), i = 1, N)]
real(dp), parameter :: S = sum(X)*dx
logical, parameter :: l = S < 2
real(kind=merge(sp, dp, l)) :: y
if (kind(y) == sp) then
print *, "true"
else
print *, "false"
end if
print *, S
end program
Now we benchmark the compilation speed with various compilers depending on the array size N (the number of integration points).
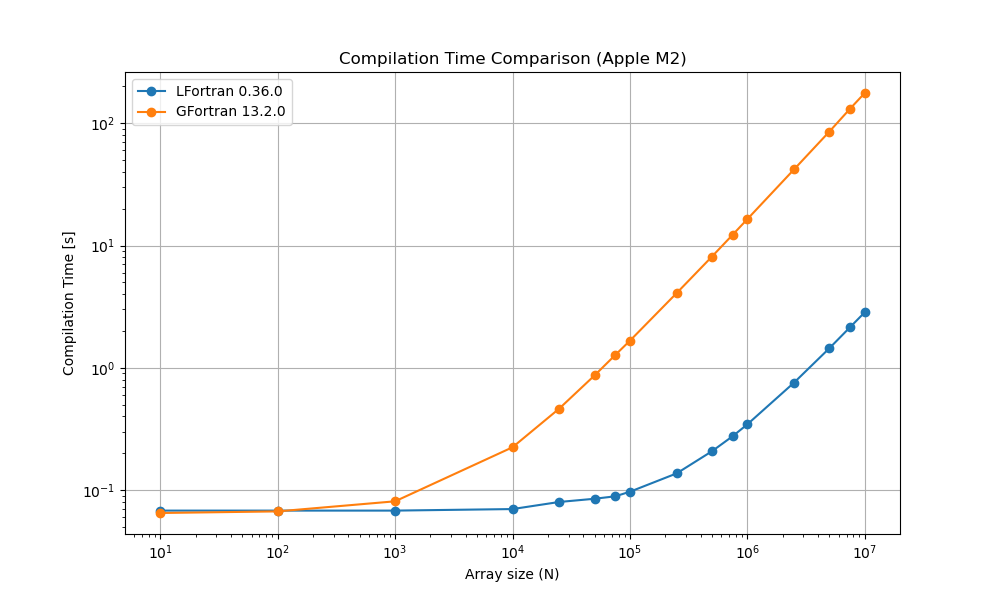
On MacBook Air M2 8GB RAM
| N | GFortran (s) | LFortran (s) | GFortran / LFortran |
|---|---|---|---|
| 10 | 0.065 | 0.068 | 0.9558823529 |
| 100 | 0.067 | 0.068 | 0.9852941176 |
| 1000 | 0.081 | 0.068 | 1.191176471 |
| 10000 | 0.224 | 0.07 | 3.2 |
| 25000 | 0.464 | 0.08 | 5.8 |
| 50000 | 0.867 | 0.085 | 10.2 |
| 75000 | 1.273 | 0.089 | 14.30337079 |
| 100000 | 1.666 | 0.097 | 17.17525773 |
| 250000 | 4.083 | 0.137 | 29.80291971 |
| 500000 | 8.128 | 0.208 | 39.07692308 |
| 750000 | 12.25 | 0.276 | 44.38405797 |
| 1000000 | 16.431 | 0.345 | 47.62608696 |
| 2500000 | 41.947 | 0.757 | 55.41215324 |
| 5000000 | 85.506 | 1.447 | 59.09191431 |
| 7500000 | 131.474 | 2.15 | 61.15069767 |
| 10000000 | 176.646 | 2.846 | 62.06816585 |
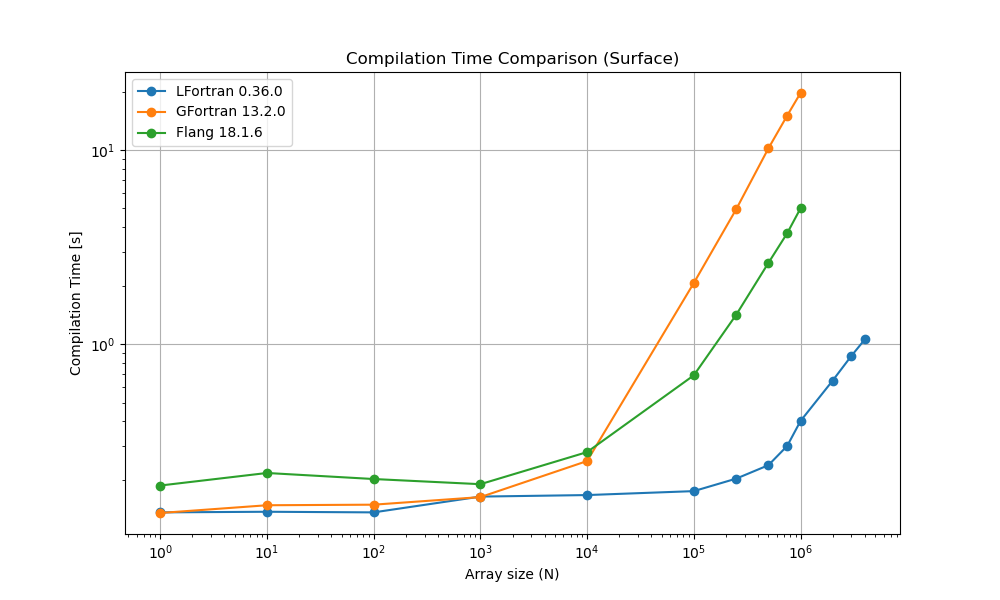
On Surface Laptop 5; WSL, Ubuntu 22.04, 12th Gen Intel(R) Core(TM) i7-1265U
| N | LFortran | GFortran | Flang | GFortran / LFortran | Flang / LFortran |
|---|---|---|---|---|---|
| 1 | 0.136 | 0.135 | 0.187 | 0.992647059 | 1.375 |
| 10 | 0.137 | 0.148 | 0.217 | 1.080291971 | 1.583941606 |
| 100 | 0.136 | 0.149 | 0.202 | 1.095588235 | 1.485294118 |
| 1.00E+03 | 0.164 | 0.163 | 0.19 | 0.993902439 | 1.158536585 |
| 1.00E+04 | 0.167 | 0.25 | 0.278 | 1.497005988 | 1.664670659 |
| 1.00E+05 | 0.175 | 2.066 | 0.691 | 11.80571429 | 3.948571429 |
| 2.50E+05 | 0.203 | 4.962 | 1.419 | 24.44334975 | 6.990147783 |
| 5.00E+05 | 0.238 | 10.199 | 2.621 | 42.85294118 | 11.01260504 |
| 7.50E+05 | 0.299 | 15.047 | 3.728 | 50.32441472 | 12.46822742 |
| 1.00E+06 | 0.402 | 19.671 | 5.009 | 48.93283582 | 12.460199 |
| 2.00E+06 | 0.649 | - | - | - | - |
| 3.00E+06 | 0.871 | - | - | - | - |
| 4.00E+06 | 1.057 | - | - | - | - |
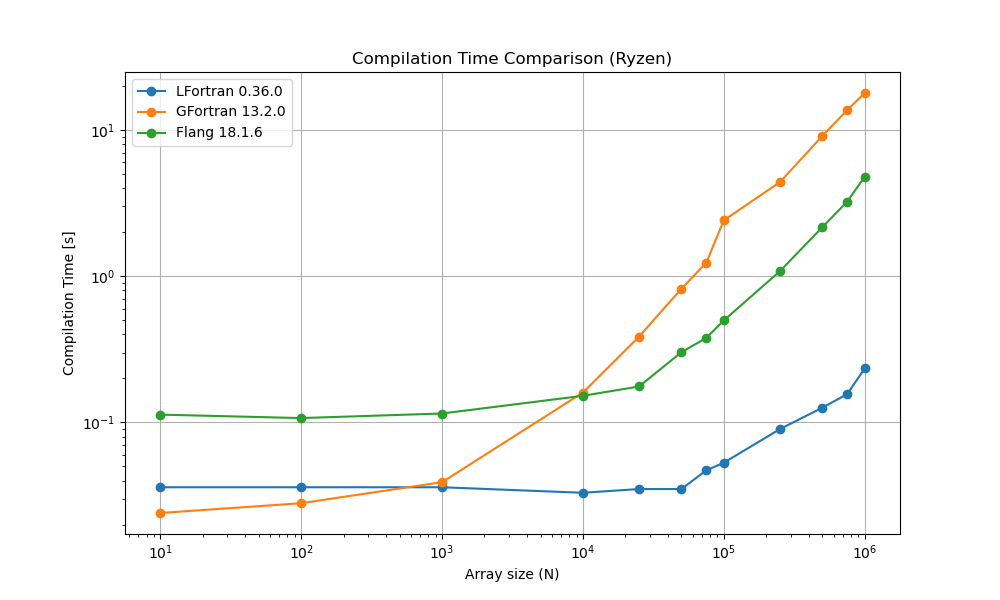
On Ryzen 7 5800, 16G RAM, Ubuntu
| N | LFortran | GFortran | Flang | GFortran / LFortran | Flang / LFortran |
|---|---|---|---|---|---|
| 10 | 0.036 | 0.024 | 0.113 | 0.666667 | 3.138889 |
| 100 | 0.036 | 0.028 | 0.107 | 0.777778 | 2.972222 |
| 1000 | 0.036 | 0.039 | 0.115 | 1.083333 | 3.194444 |
| 10000 | 0.033 | 0.160 | 0.152 | 4.848485 | 4.606061 |
| 25000 | 0.035 | 0.386 | 0.176 | 11.028571 | 5.028571 |
| 50000 | 0.035 | 0.821 | 0.302 | 23.457143 | 8.628571 |
| 75000 | 0.047 | 1.236 | 0.378 | 26.297872 | 8.042553 |
| 100000 | 0.053 | 2.412 | 0.498 | 45.509434 | 9.396226 |
| 250000 | 0.090 | 4.399 | 1.082 | 48.877778 | 12.022222 |
| 500000 | 0.126 | 9.093 | 2.162 | 72.166667 | 17.158730 |
| 750000 | 0.156 | 13.679 | 3.234 | 87.685897 | 20.730769 |
| 1000000 | 0.234 | 17.893 | 4.792 | 76.465812 | 20.478632 |
The above tables are visualized in the graphs below:
How to Run the Benchmark Yourself
We installed LFortran, GFortran and Flang using Conda, that way you can install exactly the same binary as well, and that way if there is any issue how each compiler was compiled into the conda package, one can simply send a PR against the conda-forge repository to improve it, and the compiler developers can ensure that their compiler is compiled correctly with maximum performance.
Create a conda environment with exactly the versions that we used:
mamba create -n ct lfortran=0.36.0 gfortran=13.2.0 flang=18.1.6
mamba activate ct
Benchmark the speed of compilation:
time lfortran compile_time.f90 -o a.out
time gfortran -fmax-array-constructor=10000000 compile_time.f90 -o a.out
time flang-new compile_time.f90 -o a.out
Note: Flang currently does not have a conda package for Apple Silicon, so we only benchmarked it on Linux.
Development Overview
The roots of development lead us to PR#3564 which aimed to handle compile time evaluation of elemental functions. At that time we only had ArrayConstant represented in ASR grammar as:
ArrayConstant(expr* args, ttype type, arraystorage storage_format)
That means ArrayConstant was being used to handle both compiletime and runtime values. Thereafter we decided to split it into ArrayConstructor for handling runtime value and ArrayConstant which contains compiletime values.
Thus in PR#3579, the grammar was changed to:
ArrayConstructor(expr* args, ttype type, expr? value, arraystorage storage_format) ArrayConstant(expr* args, ttype type, arraystorage storage_format)
From then, ArrayConstant is only allowed other *Constant in it (but not another ArrayConstant) whereas the ArrayConstructor is allowed other nodes. For example [sin(x), y], or two ArrayConstants.
Later, we realized that we should improve upon the internal representation of ArrayConstant further, so we documented approach at issue#3581.
Now,ArrayConstant should contain a type (that includes kind) of the element, shape, and then a pointer to contiguous data. Thus the ASR grammar was changed to:
ArrayConstant(int n_data, void data, ttype type, arraystorage storage_format)
Implementation details can be found at PR#3859.
There were also a bunch of minor patches that contributed to performance improvement for evaluating compile time values.
Contributing
Help us get to beta faster by reporting bugs and submitting PRs to fix things. We will help you get started, no prior compiler experience needed.
Acknowledgements
We want to thank:
- Sovereign Tech Fund (STF)
- NumFOCUS
- QuantStack
- Google Summer of Code
- GSI Technology
- LANL
- Our GitHub, OpenCollective and NumFOCUS sponsors
- All our contributors (78 so far!)
Discussions
- Fortran Discourse: https://fortran-lang.discourse.group/t/compile-time-computation-example-now-works-with-lfortran/8139
- Twitter: https://twitter.com/lfortranorg/status/1797999009849868783
- LinkedIn: https://www.linkedin.com/posts/pranavgoswami1_fortran-arrays-performance-activity-7203772703198052352-Q1RR/